zhuzilin's Blog
about
6.824 阅读笔记2 —— Raft
date: 2019-09-21
tags: OS “distributed” 6.824
In Search of an Understandable Consensus Algorithm
5 The Raft consensus algorithm
Raft是一个用来处理replicated log的算法。文中的图2进行了算法要点的总结,图3展示了算法的主要特点。下面让我们来详细介绍一下这个算法。

Raft首先要选出一个leader,并让leader负责管理replicated log。leader从client处得到log entries,并把它们复制给其他server,以及告诉这些server什么时候可以安全地执行这些log entries。选出这个leader简化了管理,因为其可以自己做决定。当一个leader fail或者失联了,就需要重新选举leader。
鉴于上述基于leader的方法,raft把consensus problem转化为3个相对独立的子问题:
- Leader election: 当当前leader fail的时候该如何选举新leader。
- Log replication: leader需要从client接受log entries,并把这些entries复制给其他server,强制其他的log和它自己的一样(agree)。
- Safety: raft的key safety property是指如果一个server已经根据某一特殊的log entry修改了其state machine,那么其他server不能对同一个log index对应不同的command。(这个特点5.4会详细讲,现在说的有点不清楚)
这个section除了讲上面的3个问题以外,还会讨论一下availability的问题和role of timing。
5.1 Raft basics
一个Raft server包含多个server,常见的是5个服务器,允许系统有2个failure。在任何时候,一个server只会在如下的3个状态中leader, follower, candidate。在正常操作中,只会有1个leader,其他的服务器都是follower。follower不能做任何主动的操作,他们只能回复leader和candidate的request。leader会处理所有的client request(如果一个client联系了一个follower,follower会把这个请求转给leader)。candidate则是用来选举新的leader用的状态。3个状态之间的转化关系如下:
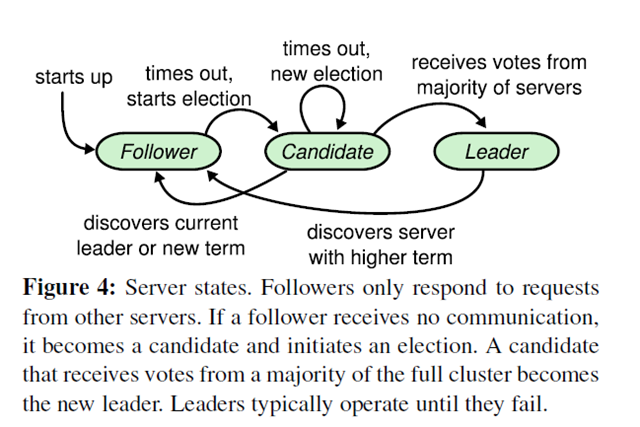
raft把时间分割成任意长的term(任期)。term使用连续整数标记的。每个term以一个election开始,在选举中,1个或多个candidate试着去按照5.2中介绍的方法成为leader。如果一个candidate赢得了选举,那么其会作为这一任期的leader。有的时候选举会出现平票,那么这个term没有leader,会直接开始一个新的term(同时开始一个新选举)。raft保证每个term最多只有1个leader。terms的一个例子如下:

不同的服务器可能在不同的时间才能发现term的更替,并且在一些情况下一个server可能并没有观察到(observe)一个election,甚至某一个term。term在raft中作为logical clock,并且servers允许detect obsolete information such as stale leaders。每个服务器存储了一个current term number,其随时间单增。任何时候两个服务器进行交流都会交换当前term编号。如果一个服务其的当前term小于另一个的,那么它会更新为这个大的值。如果一个candidate或者leader发现自己的term number已经过期,其会拿上转化为follower。如果一个server收到了一个stale term number(应该是指过期了的),它会拒绝该请求。
Raft服务器利用RPC进行交流。最基本的consensus algorithm仅依赖2种RPC:
RequestVoteRPC: 由candidate在选举时发起(见5.2节)AppendEntriesRPC: 由leader在复制log entires并提供某种heartbeat的时候使用
第7节加入了一个用来传输snapshots的RPC。当服务器没有即使收到回复,它们会重试RPC,并且会并行发送RPC。
5.2 Leader election
Raft用一个heartbeat mechanism来触发leader election。当server启动的时候,他们的初始状态是follower。一个server会持续作为follower只要其收到leader和candidate发送过来的有效RPC。Leader会周期性发送heartbeat(没有log entries的AppendEntries RPC)给所有的follower来maintain its authority。如果一个follower一段时间没有收到任何通信(被称为election timeout)那么它会认为不存在viable leader,并开始election以选举新的leader。
为了开始election,一个follower会把自己的current term number加1并把自己的状态改为candidate。然后其会为自己投一票并给集群中所有其他的server发一个RequestVote RPC。只要一下的三件事情之一发生的时候,一个candidate才会改变状态:
- 该candidate赢得了election
- 另一个server成为了leader
- 一段时间过去,没有winner
下面对上述三种情况一一介绍:
当一个candidate在同一个term获得大多数server的投票的时候,其赢得选举。每个server最多只能投给一个server,谁先来先投给谁(注意5.4中给投票加了一些限制)。大多数规则保证了最多1个获胜的candidate。当一个candidate获胜的时候,他就变成了leader,他会之后想所有其他server发送heartbeat以建立authority并阻止新的选举。
在等待投票的时候,candidate可能还会收到AppendEntries RPC(注意这里是包括heartbeat的)。如果这个发送RPC的leader的term大于等于candidate的term,那么candidate就把这个leader视为legitimate leader,并把自己的状态调为follower。如果RPC的term比candidate的小,那么candidate会拒绝这个RPC并继续其candidate状态。
第三种情况就是一个candidate既没有赢也没有输,及许多follower几乎同时成为candidate从而分了票,导致没有candidate获得大多数的vote。如果发生了这种情况,每个candidate会time out并重新开始election(term也会加1)。不过如果不加入别的衡量标准,这种无结果可能会无限延续。
Raft通过随机化election timeout来保证分票的情况很少出现,且很快可以被解决。为了防止split vote,election timeout被设为一个区间内的随机值(如150~300ms)。这样使得大多数时候只有1个server会timeout,其将赢得选举。同样,当每个candidate restart election的时候,也是会等待一个上述随机的时间。9.3中展示了这种方法可以很快得到leader。
Election是我们为了方便理解而做出的设计,最开始我们考虑的是给所有server一个rank,从而方便从candidate中进行选择。我们发现这种设计会在availability上有一些小问题(一个低rank的server可能会在一个高rank的server fail的情况下timeout,但是如果其迅速timeout,可能会导致之前进行的progress都被重置,而一直在进行election...这里没太懂...)
5.3 Log replication
当选举出一个leader的时候,其开始处理client request。每个client request都包含了一个command。leader会把这个command作为一个新的entries append到自己的log后面,并向所有其他server发送AppendEntries。当entries被成功复制了之后(怎么复制的下面会讲)leader会把这个entry里的command施加在自己的state machine上并返回执行得到的结果返回给client。如果follower crash或者运行的很慢,或者网络丢包(也就是说leader很久没收到response),leader会重发AppendEntries直到所有follower存储了所有的log entries。
log的组织方式如下图所示:

每个log entry包含了一个command和一个存入这个command时候的leader的term number。term number是用来在log之间的detect inconsistencies并保证一些性质用的。每个log entry也有有一个整数的index identity来表示其在log中的位置。
leader会决定什么时候可以安全地apply a log entry to the state machine。被applied的entry被称为committed。raft保证committed entries为durable且最终会被所有的available的state machine所执行。当一个log entry已经被复制到超过半数server上了的时候,就会被committed,如上图的7号entry。这也会commit在这条entry之前的所有entry。5.4中会讨论当leader改变了之后的一些细节,且证明这种commit的方式是安全的。leader会保存committed entries中index最大的序号,并在之后的AppendEntries RPC中加入它(包括heartbeat),从而让其他的server也eventually find out。当一个follower得知某一entry已经committed,其会把这个entry施加于其local state machine。
我们设计Raft log mechanism以维持不同server上log间的high level of coherency。这不仅简化了系统的behavior也当系统更易预测,更是保证safety的重要元素。raft会保持如下的2条特性:
- 如果两个不同log种的entries有相同的index和term,他们存储的是同一个command。
- 如果2个entries在不同log种有相同的index和term,则这两个log在这两条entries之前完全相同。
第一条是因为一个leader只能在同一个term下给一个index对应最多一条entry,且log entry永远不会改变其在log中的位置。
第二条是通过AppendEntries中的一个简单的consistency check来保证的:当发送一个AppendEntries RPC的时候,leader会包含当前发送entry的前一条的index和term,如果follower里没有相同index和term的entry,就会拒绝这一RPC。
在正常的操作下,leader的log和followers的相互保持consistent,所以AppendEntries的这consistency check总是成功的。不过如果leader crash,就会导致发生inconsistent(老leader可能还没有完全复制所有的entries就挂了)。这些inconsistencies可能会在一系列leader和follower的crash下相互组合。下图就是inconsistency的一种情况:

一个follower可能会缺失现在的leader上的entry,可能会有leader上没有的,或者两种情况同时发生。missing and extraneous entries may span multiple terms。
在raft中,leader通过强制要求follower复制其log来解决consistency。这意味着conflict的entry会被overwritten。5.4说明了这种做法是安全的。
为了让一个follower的log和leader的相consistent,leader需要找到两者间agree的最后一个entry,删除follower在那之后的所有log,并把那之后leader的entry发给follower。这些操作都会在AppendEntries的consistency check中完成。leader会为每一个follower存一个nextIndex,也就是leader会传给这个follower的下一个entry。当一个leader first come to power,它会初始化所有的nextIndex为其下一个entry的index,如上图中,nextIndex会被初始化为11。如果一个follower没能通过AppendEntries的consistency check,也就是它拒绝了leader的request,leader会把它的nextIndex减一。最终nextIndex会降到leader和follower的log相互match,当这个match发生的时候,AppendEntries就成功了,其会删除follower这个match的位置后面的所有log,并换上leader的(所以leader要发一串过去???)。所以一旦AppendEntries成功了,leader和follower的log就是相互consistent的,且这种关系将持续到这个term结束。
如果需要的话,可以用protocol来减少被拒绝的AppendEntries的个数。比如说,当拒绝一个AppendEntries的时候,follower可以保存conflicting entry的term与这个follower存储的在这个term中的最小的index。这样leader就可以跳过所有这个term中的entry了。不过在实际操作中,我们怀疑这种做法是不是有用,因为实际中往往只有很少的conflict。
利用以上机制,leader不需要做任何特殊操作就可以恢复log consistency。其只需要进行正常操作,and the logs automatically converge in response to failure of the AppendEntries consistency check。一个leader从不会重写或删除自己的entry。
这种log replication机制展现了section 2中提到的raft的性质:只要超过半数的server are up,raft可以接受、复制并执行新log entries。在大多数情况下,一个entry可以在1 RPC round下复制到过半数server,少数慢的follower不会影响其性能。
5.4 Safety
前面两节展示了raft是如何选举leader与复制entry的,然而当前描述的机制不足以保证所有state machine都以相同的顺序执行相同的command。例如,一个follower可能会没有办法收到leader发送的多个log entries,之后它却被选举为了leader,从而用之后的entry重写了它没收到的这些,从而导致不同的state machine可能会执行不同的序列。
这一节通过给能够选举为leader的server加一个限制来完成raft算法。这个限制保证了任意term的leader都包含了之前一个term被commit的所有entries。鉴于这个election restriction,我们给commitment也加了更精确的规则。最后我们简单证明一下如何达成这一限制以及为什么这可以让所有的状态机都有正确的behavior。
5.4.1 Election restriction
在任何leader-based consensus算法中,leader必须eventually存储所有committed log entries。在一些consensus algorithms,如viewstamp replication中,一个leader可以在最初的时候不包含所有committed entries。这些算法包含了额外的机制来identify the missing entries并传输给new leader,或者在选举过程中,或者在刚刚完成选举后。不幸的是,这会导致加入明显复杂的机制。raft直接通过要求new leader在election开始的时候包含上一个term的所有committed entries,而不需要额外的传输。这意味着entries只能从leader向follower单向传输,且leader从不覆写自己的entry。
raft用voting process来防止一个不包含所有committed entries的candidate成为leader。一个candidate需要连接超过半数的server以当选,这意味着每个committed entry必须存在于至少一个上述server中。如果candidate log和那半数中的log至少一样up-to-date(up-to-date的定义下面会写),那么它一定包含了所有的committed entries。RequestVote RPC实现了这样的限制:RPC包含了candidate log的信息,voter只有在candidate比自己up-to-date的情况下才会投票。
Raft通过比较最后一个entries的index和term来比较两个log那个更up-to-date。如果log有不同的term,term大的更up-to-date,如果term相同,哪个log更长哪个更up-to-date。(这里更长就不太懂了....)(注意这里的term不一定是candidate的这个election的term)
5.4.2 Committing entries from previous terms
如5.3所属,一个leader知道一个entry被commited如果超过半数的server已经存储了这一entry。如果在commit之前leader crash了,未来的leader会试着完成复制这一entry。不过一个leader不能马上推测出上一term中的某一entry已经被committed了,所以还是可能会重写他们。下图展示了一个old entry虽然被存在了超过半数的server上,但是仍然被重写的例子:

为了避免上图的问题(大致就是一个entry明明已经被复制成功了,但是在commit之前leader就挂了,结果一个被接收到这个entry的server当了leader,而覆盖了这些entry,导致白复制了,但是我觉得(c)不应该是s2和s3都是包含4的吗,也就是和(e)一样,啥时候回出现(c)的情况呀...),raft从不通过对之前term的entry进行复制的计数来commit。只能commit当前term的entry,并且在commit的时候会把这个entry之前的entry都commit掉。实际上有一些情况leader是可以推测处old log已经被committed了(比如一个entry被存在了所有server上),不过为了简便,raft采用一种比较保守的处理方法。
raft在commitment rule中加入这一条是因为当一个leader复制之前的term的entries时,那些entry会保留自己额term number。在其他的consensus algorithms中,如果一个新leader重新复制之前term的entry,需要改为新的term number。raft的这个策略让log entry比较好reason about。并且,raft中的新leader会发送更少的来自于之前term的entries(别的算法必须发送冗余的log entries来对这些entries进行重新计数来commit他们)(这里没太懂...可能要等看了其他算法再说...)
5.4.3 Safety argument
基于完整的raft算法,我们可以
如果需要实现raft,请参照文中的figure 2