zhuzilin's Blog
about
6.828 lab2 Memory Management
date: 2019-02-24
tags: OS 6.828
Part 1: Physical Page Management
写一个physical page allocator。注意分配出来的pages就是表示了整个物理内存,但是记录的是每个page对应的虚拟地址。用物理地址来找到对应的page,然后用这个page的虚拟地址来得到其实际存的东西。
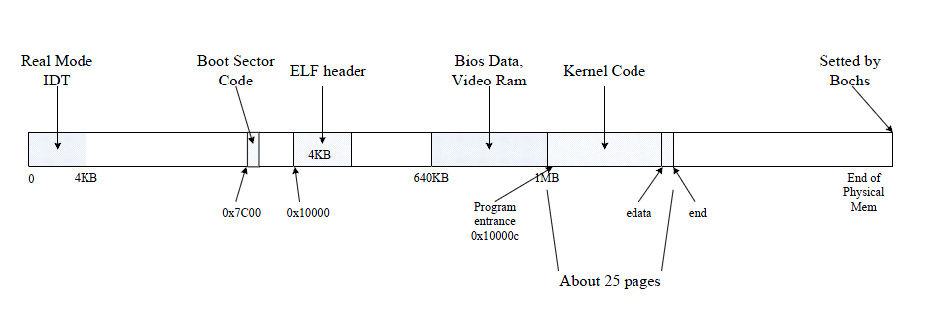
这里的内存初始化就是为了让物理内存有这样的结构:
Exercise 1
需要修改如下几个函数:
boot_alloc()
mem_init() (only up to the call to check_page_free_list(1))
page_init()
page_alloc()
page_free()首先是boot_alloc():
// This simple physical memory allocator is used only while JOS is setting
// up its virtual memory system. page_alloc() is the real allocator.
//
// If n>0, allocates enough pages of contiguous physical memory to hold 'n'
// bytes. Doesn't initialize the memory. Returns a kernel virtual address.
//
// If n==0, returns the address of the next free page without allocating
// anything.
//
// If we're out of memory, boot_alloc should panic.
// This function may ONLY be used during initialization,
// before the page_free_list list has been set up.
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
// Initialize nextfree if this is the first time.
// 'end' is a magic symbol automatically generated by the linker,
// which points to the end of the kernel's bss segment:
// the first virtual address that the linker did *not* assign
// to any kernel code or global variables.
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// Allocate a chunk large enough to hold 'n' bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
//
// LAB 2: Your code here.
if(n == 0)
return nextfree;
result = nextfree;
nextfree += ROUNDUP(n, PGSIZE);
return result;
}从注释里面可以看出,这里是分配物理内存,分配的就是连续的内存,所以直接加就好了。注意这个函数返回的是VA,所以如果需要使用物理内存,就要用PADDR()这个宏。
之后是mem_init(),注意这个函数只设置好kernel部分的内存。mem_init先分配了kernel的page directory。
//////////////////////////////////////////////////////////////////////
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// Your code goes here:
pages = (struct PageInfo *)boot_alloc(sizeof(struct PageInfo)*npages);
memset(pages, 0, sizeof(struct PageInfo)*npages);在这之后,我们需要操作的就是PageInfo这个struct了
/*
* Page descriptor structures, mapped at UPAGES.
* Read/write to the kernel, read-only to user programs.
*
* Each struct PageInfo stores metadata for one physical page.
* Is it NOT the physical page itself, but there is a one-to-one
* correspondence between physical pages and struct PageInfo's.
* You can map a struct PageInfo * to the corresponding physical address
* with page2pa() in kern/pmap.h.
*/
struct PageInfo {
// Next page on the free list.
struct PageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries)
// to this page, for pages allocated using page_alloc.
// Pages allocated at boot time using pmap.c's
// boot_alloc do not have valid reference count fields.
uint16_t pp_ref;
};这个结构记录了一个page的meta data,其中保存了下一个free page的地址与这个page被ref的次数。而实际page的物理内存,用其和pages这个变量的地址的距离来衡量,之后用到的page2kva会看到。
然后我们来修改page_init
//
// Initialize page structure and memory free list.
// After this is done, NEVER use boot_alloc again. ONLY use the page
// allocator functions below to allocate and deallocate physical
// memory via the page_free_list.
//
void
page_init(void)
{
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
for (i = 1; i < npages_basemem; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
for(i = PADDR(boot_alloc(0))/PGSIZE; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}因为kernel是分配在extended memory里面,加上mem_init的前面分配的page dir以及相关的内存,所以后一部分应该跳过这些地方。然后PADDR就是把kernel里面的VA转化为PA。
然后写page_alloc,从page_free_list里面提取出来下一个非空的page
// Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire
// returned physical page with '\0' bytes. Does NOT increment the reference
// count of the page - the caller must do these if necessary (either explicitly
// or via page_insert).
//
// Be sure to set the pp_link field of the allocated page to NULL so
// page_free can check for double-free bugs.
//
// Returns NULL if out of free memory.
//
// Hint: use page2kva and memset
struct PageInfo *
page_alloc(int alloc_flags)
{
// Fill this function in
struct PageInfo *ret = page_free_list;
if(!page_free_list)
return NULL;
page_free_list = ret->pp_link;
ret->pp_link = NULL;
if(alloc_flags & ALLOC_ZERO)
memset(page2kva(ret), 0, PGSIZE);
return ret;
}注意这里面的page2kva函数是把一个page的PageInfo地址转化为其对应的kernel VA,具体的做法就是看pp是pages后面的第几个PageInfo,然后这个序号就是这个page的物理内存的前20位,因为是对齐的,所以后12位都是0,得到这个物理地址之后,加KERNBASE就找到了这个page的物虚拟内存。注意这里把取出来的ret的后面变为空了,这个举动单纯就是用来在page_free里面进行检查的。
然后最后一个page_free。
// Return a page to the free list.
// (This function should only be called when pp->pp_ref reaches 0.)
//
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if(pp->pp_ref || pp->pp_link)
panic("pp free error.");
pp->pp_link = page_free_list;
page_free_list = pp;
}写完这部分之后,启动时会是这样:
check_page_free_list() succeeded!
check_page_alloc() succeeded!Part 2: Virtual Memory
Exercise 2
读书的部分,先跳过去。
Virtual, Linear, and Physical Addresses
Selector +--------------+ +-----------+
---------->| | | |
| Segmentation | | Paging |
Software | |-------->| |----------> RAM
Offset | Mechanism | | Mechanism |
---------->| | | |
+--------------+ +-----------+
Virtual Linear Physical在x86里面,虚拟内存由segment selector和offset within the segment组成。linear address是先用segment translation解释过的结果,之后再通过page translation得到物理内存。
一个C语言中的指针实际上是offset,在boot/boot.S里面,我们用Global Descriptor Table(GDT)来有效的把segment selector给废了
gdt:
SEG_NULL # null seg
SEG(STA_X|STA_R, 0x0, 0xffffffff) # code seg
SEG(STA_W, 0x0, 0xffffffff) # data seg所以linear address在JOS中就是等于offset。在lab 3中我们可能会设置一点segmentation以设置隐私等级,但是对于内存翻译,在JOS中我们可以忽略segmentation mechanism并只考虑page translation。
回忆在lab 1的part3,我们使用在kern/entrypgdir.c硬编码的一个page table来把物理内存中前4MB的内存进行了映射,从而让kernel能够从0xf0100000开始运行,即使其实际上是在0x00100000的物理内存加载的。我们现在就会映射整个的256MB的物理内存,从虚拟内存0xf0000000开始,并映射到一些位置。
Exercise 3
一些gdb和qemu的一些指令。
之前在boot.S我们提到过protected mode,就是在这个文件里头做的第一件事。所有的内存引用都会被翻译为虚拟内存,之后用MMU翻译为物理内存。所以说所有C中的指针都是虚拟地址。
JOS的kernel经常需要直接把地址当成整数来操作,也就是不去探究地址里存了什么。为了方便文档记录,JOS用两个类型来记录地址:uintptr_t用来表示虚拟地址,physaddr_t表示物理内存,他们实际上就是uint32_t,所以从编译器的角度并不会阻止这两个类型之中的相互赋值,而且如果直接dereference回报错,需要类型转换。对于uintptr_t可以转化为指针类型进行dereference,而对于物理地址,不能直接dereference。
简而言之:
| C type | Address type |
|---|---|
T* |
Virtual |
uintptr_t |
Virtual |
physaddr_t |
Physical |
JOS kernel经常需要读写只知道物理地址的内存。比如说,mapping a page table可能需要分配物理内存来存储page directory,并对应的呃呃你存。但是kernel不能bypass virtual address translation,所以不能直接load and store物理内存。JOS把所有的从0开始的物理内存映射到从0xf0000000开始的虚拟内存是为了帮助kernel读写其只知道物理地址的内存。也就是直接把物理内存加0xf0000000从而转化为对应的虚拟内存。应该用KADDR(pa)。
有的时候还需要从虚拟地址转化为物理地址,也是相似的,需要减,用PADDR(va)。
Reference counting
之后的lab,经常会需要把同一个物理地址同时转化为多个虚拟内存。那么就需要对引用进行计数,这也就是PageInfo中的pp_ref。当这个值为0的时候就可以释放掉了(就像垃圾回收)。换句话说,这个值应该是UTOP下面所有的page tables提及到总次数(UTOP上的内存一般都是kernel相关的,一般都不会释放了,所以不需要对他们计数)。我们也需要记录指向page directory pages的指针数,同时page directory指向page table pages的引用数。
注意用page_alloc的时候,分配出来的引用计数都是0,调用完一些函数之后需要手动添加引用数。
Page Table Management
Exercise 4
修改这些函数:
pgdir_walk()
boot_map_region()
page_lookup()
page_remove()
page_insert()首先是pgdir_walk,类似于xv6里面的walkpgdir。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
pde_t *pde = &pgdir[PDX(va)];
if(!(*pde & PTE_P)) {
if(!create)
return NULL;
struct PageInfo *pgtab = page_alloc(ALLOC_ZERO);
if(!pgtab)
return NULL;
pgtab->pp_ref++;
*pde = page2pa(pgtab) | PTE_P | PTE_U | PTE_W;
}
return (pte_t*)(KADDR(PTE_ADDR(*pde))) + PTX(va);
}这里面的主要逻辑是先用前10位找到va对应的pde,如果需要创建,那么就创建创建一个page,并且把这个page的地址前12位去掉(这就是page2pa干的事),然后把空出来的那12位附上值,给pde对应的值付为这个page对应的page table的地址。最后正常的返回。
然后是boot_map_region,类似于xv6的mappages,不过注意这里的size已经是PGSIZE的整数倍了。
// Map [va, va+size) of virtual address space to physical [pa, pa+size)
// in the page table rooted at pgdir. Size is a multiple of PGSIZE, and
// va and pa are both page-aligned.
// Use permission bits perm|PTE_P for the entries.
//
// This function is only intended to set up the ``static'' mappings
// above UTOP. As such, it should *not* change the pp_ref field on the
// mapped pages.
//
// Hint: the TA solution uses pgdir_walk
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
for(uint32_t i=0; i<size; i+=PGSIZE) {
pte_t *pte = pgdir_walk(pgdir, (const void *)va, true);
*pte = pa | perm | PTE_P;
va += PGSIZE;
pa += PGSIZE;
}
}注意这里面va, pa都是相关于PGSIZE对齐了的,也就是只剩下了20位。
之后是写page_insert。
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir, va, true);
if(!pte)
return -E_NO_MEM;
pp->pp_ref++;
if(*pte & PTE_P)
page_remove(pgdir, va);
*pte = page2pa(pp) | perm | PTE_P;
return 0;
}就是用了一下前面的接口。
然后是page_lookup。
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir, va, false);
if(!pte || !(*pte & PTE_P))
return NULL;
if(pte_store)
*pte_store = pte;
return pa2page(PTE_ADDR(*pte));
}和page_insert很像。
page_remove
void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t *pte = NULL;
struct PageInfo *pp = pgdir_walk(pgdir, va, &pte);
if(!pp)
return;
*pte = 0;
page_decref(pp);
tlb_invalidate(pgdir, va);
}这里面不太好理解的是最后的这个tlb_invalidate,这个函数是调用再x86.h中的invlpg函数,也就是汇编中的invlpg指令,详细的理解可以看这里,大致就是会刷新Translation Lookaside Buffer(TLB),其缓存了线性地址到物理地址的映射关系。
然后运行一下。得到:
check_page_free_list() succeeded!
check_page_alloc() succeeded!
check_page() succeeded!Part 3: Kernel Address Space
JOS把32位的线性地址分为两个部分。User environments(进程),会控制lower part的layout和content,而kernel会对应upper part。这两者的分界线是inc/memlayout.h中的ULIM。大约给kernel保存了256MB。This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel's virtual address space to map in a user environment below it at the same time.(这个this is why没明白)。
Permissions and Fault Isolation
User environment对于ULIM之下有访问权限。而对于[UTOP, ULIM)之间的内存,是kernel 与user environment有相同的权限,可读不可写。这部分是用来把kernel中的一部分信息给user。最下面的部分就是给user的,user可以自己设置权限。
Initializing the Kernel Address Space
现在需要设置的是UTOP之上的内存。
Exercise 5
//////////////////////////////////////////////////////////////////////
// Now we set up virtual memory
//////////////////////////////////////////////////////////////////////
// Map 'pages' read-only by the user at linear address UPAGES
// Permissions:
// - the new image at UPAGES -- kernel R, user R
// (ie. perm = PTE_U | PTE_P)
// - pages itself -- kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U | PTE_P);
//////////////////////////////////////////////////////////////////////
// Use the physical memory that 'bootstack' refers to as the kernel
// stack. The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P);
//////////////////////////////////////////////////////////////////////
// Map all of physical memory at KERNBASE.
// Ie. the VA range [KERNBASE, 2^32) should map to
// the PA range [0, 2^32 - KERNBASE)
// We might not have 2^32 - KERNBASE bytes of physical memory, but
// we just set up the mapping anyway.
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, 0x10000000, 0, PTE_W | PTE_P);根据注释加入映射。
之后再运行就有:
check_page_free_list() succeeded!
check_page_alloc() succeeded!
check_page() succeeded!
check_kern_pgdir() succeeded!
check_page_free_list() succeeded!
check_page_installed_pgdir() succeeded!下面有几个问题。
Address Space Layout Alternatives
本次用的这种映射的layout不是唯一解。比如也可以是kernel在low linear address,而user在upper。不过x86一般不这么做,原因是为了和8086有backward-compatibility。
还可以设计kernel使其不用为自己不保存任何固定的内存,而是让用户能更有效的使用4G的内存。这里有很多Challenge,之后有时间再说吧。
写完了之后跑一些测试:
running JOS: (0.5s)
Physical page allocator: OK
Page management: OK
Kernel page directory: OK
Page management 2: OK
Score: 70/70