zhuzilin's Blog
about
6.828 总结
date: 2019-03-26
tags: OS 6.828
Boot Loader
首先当机器启动的时候,会自动加载BIOS。BIOS会检查有无bootable disk,如果有的话,会加载其boot loader(实际上就是加载boot loader)的ELF,也就是boot loader对应的二进制文件。其位于第一个IDE disk的第一个sector,之后的sector就是kernel了。
然后boot loader会首先把处理器从16位的real mode转化为32位的protected mode,然后读一个page进来,也就是读进来kernel的ELF header,通过其ELF header把kernel一个sector一个sector地读进来,然后跳转到kernel ELF header里面记录的入口,从而进入kernel。
值得注意的是kernel和boot loader的ELF的不同。也就是kernel的LMA和VMA是不同的,也就是加载到内存的位置和开始运行的位置是不同的。这是因为kernel额VMA是虚拟地址,其实际映射是0x00000000到0x0fffffff映射到0xf0000000到0xffffffff。所以即使VMA是高地址的0xf0100000实际上运行的时候对应的物理地址还是0x00100000,也就是LMA对应的地址。
Isolation mechanism
kernel通过硬件机制辅助来进行process isolation。硬件上的user/kernel mode flag,在x86上叫CPL,是%cs的后两位,CPL=0就是kernel mode,=3就是user mode。通过给几个permissible kernel entry points来跳到kernel里面去,这样就可以防止在转换的时候用户可以破坏Kernel。
对内存的隔离是利用address space,其目的是可以让每个进程有内存来访问自己的code,variables,heap,stack 并不访问其他的内存。
Interrupt, System calls and Exceptions
这3类会触发trap。
- Exceptions (page fault, divide by zero)
- System calls (
INT, intended exception) - Interrupts (devices want attention)
注意在术语上trap是被当前进程引发的,如system call,而interrupt是由外界device触发的。
trap()函数是如何知道哪个设备出发了中断?
- kernel设置LAPIC/IOAPIC ,把某个类型的中断设置为对应的vector number
- page fault也有vectors
- LAPIC/IOAPIC是PC的常规硬件,其中每个cpu有一个LAPIC
- IDT (interrupt descriptor table)用vector number来联系一个instruction address
- 这个table的内容是怎么设置的可以看下面的
SETGATE函数。 - IDT的格式是由Intel定义的,由kernel设置的
- 这个table的内容是怎么设置的可以看下面的
- 每个vector都会跳到
alltraps - CPU会通过IDT发送各种trap,其中lower 32 IDT entries有特殊的含义。
- 在xv6中,system call(IRQ)被设置为
0x40.
diagram:
IRQ or trap, IDT table, vectors, alltraps
IDT:
0: divide by zero
13: general protection
14: page fault
32-255: device IRQs
32: timer
33: keyboard
46: IDE
64: INTxv6会在main.c中的lapicinit()、ioapicinit()与tvinit()来设置好interrupt vector。
tvinit中大多数都是机械性的设置,唯有T_SYSCALL里面设置了istrap=1,也就是让系统在进行system call的时候仍然保留中断,而其他的device interrupt就不保留了。
思考两个问题(我现在还不明白...)
- 为什么在system call的过程中允许中断?
- 为什么在interrupt handing之中disable interrupt。
注意因为JOS只有一个kernel stack,而xv6有多个,所以JOS不允许在kernel中进行中断。
System Call
system call的具体流程如下:
在xv6中,一个像shell这样的用户应用,会include user.h,这里定义了用户端能够使用的所有system call的函数。而这些函数的定义都在usys.S中,具体如下:
#define SYSCALL(name) \
.globl name; \
name: \
movl $SYS_ ## name, %eax; \
int $T_SYSCALL; \
ret所以实际上,在shell中使用write函数,就是会在汇编中调用int $T_SYSCALL。
int会做的事情有:
- 切换为kernel stack(调整esp)
- 保存用户的register于kernel stack
- 设置CPL=0
- 让eip指向kernel-supplied vector。
也就是会进入vector.S,找到对应$T_SYSCALL的部分,也就是:
.globl vector64
vector64:
pushl $0
pushl $64
jmp alltraps然后进入trapasm.S中的alltraps。alltraps先保存int没有保存的寄存器,再调用trap函数,其中保存的trapframe指针就是当前的%esp。
void
trap(struct trapframe *tf)
{
if(tf->trapno == T_SYSCALL){
if(myproc()->killed)
exit();
myproc()->tf = tf;
syscall();
if(myproc()->killed)
exit();
return;
}
... ...进入trap之后,发现如果是syscall,就调用syscall(),里面有个switch会选择对应编号的syscall。注意和int相对应,在返回的途中有一个iret,相当于是做int的逆操作,也就是恢复寄存器之类的。
Virtual Memory
CPU会用一个叫MMU的东西来进行地址的转换。
CPU -> MMU -> RAM
VA PA软件只能通过VA进行load/store,而不能通过PA。
kernel告诉MMU该如何进行这个mapping
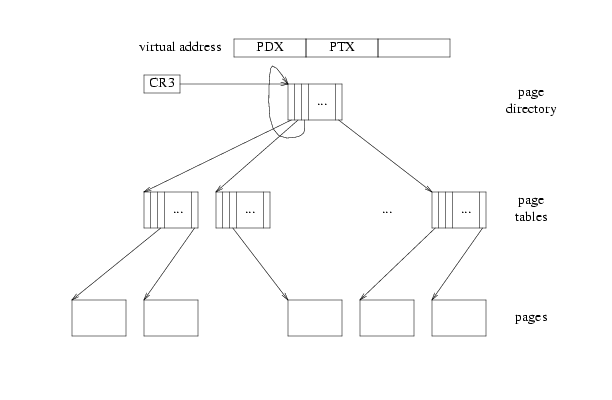
- 本质上,MMU里有一个表,key是VA, value是PA,这个表也就被称为page table
MMU还可以限制用户能够使用哪些虚拟地址。
一个page table里面有2^20个entry,被称为2^20个page table entry (PTE)。PTE的前20位就是实际上PA的前20位,其实也是PA对应的page的编号,这20位被称为physical page number (PPN)。后面的12位都是flag,记录了像PTE_P,PTE_U, PTE_W这样的entry状态。
page table被存在RAM中,MMU会读取或存储PTE。
但是2^20太大了,所以x86选择使用两层的结构。中间加入的一层称为page directory (PD)。PD也是一个array,其中每一个元素称为PDE。PDE的前20位也是PPN,这个PPN对应的page会存储一个小的page table,这个page table会指向1024个PTE。
所以PD有1024个PDE,每个PDE指向一个page table,每个page table里面有1024个PTE,所以一共2^20个PTE。
在寄存器%cr3中存储了PD的地址,MMU就是通过读%cr3来开始转化。这个转化为
- 通过
%cr3找到PD的PA,从而加载PD - 用VA的前10位找到PDE,用PDE的PPN找到PT
- 用VA的中间10位找到PTE
- 用PTE的前20位加上VA的最后12位找到VA对应的PA。
xv6的内存mapping
address space如下:
0x00000000:0x80000000 -- user addresses below KERNBASE
0x80000000:0x80100000 -- map low 1MB devices (for kernel)
0x80100000:? -- kernel instructions/data
? :0x8E000000 -- 224 MB of DRAM mapped here
0xFE000000:0x00000000 -- more memory-mapped devices对于以上的mapping,有几个注意:
-
user virtual addresses 从0开始
- 注意不同user的0会map到不同的PA
-
2GB for user heap to grow contiguously
- 不过注意这2G不是连续的物理内存,所以就不会有fragmentation problem
-
kernel和user都被map了
- 为了方便进行system call或interrupt
- 方便kernel读写用户内存
-
kernel永远都被map在固定位置:
- 方便切换进程
-
kernel线性映射(pa x mapped at va x+0x80000000)
- 方便kernel读写物理内存
-
这种情况最大的进程能有:
0x80000000,也就是2G内存。
初始化
最开始bootmain运行之后会进入entry.S,这里面会先直接把%cr3赋值为entrypgdir。
# Set page directory
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3entrypgdir的映射如下:
// The boot page table used in entry.S and entryother.S.
// Page directories (and page tables) must start on page boundaries,
// hence the __aligned__ attribute.
// PTE_PS in a page directory entry enables 4Mbyte pages.
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};里面的注释写了,把VA的0x00000000:0x00400000和0x80000000:0x80400000都映射到PA的0x00000000:0x00400000。会先初始化kernel的address space,再进行user的。
kinit1(end, P2V(4*1024*1024)); // phys page allocator
kvmalloc(); // kernel page table
...
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
userinit(); // first user process先说kernel的一头一尾:kinit1和kinit2。这里的P2V就是加上KERNBASE,然后end是已经在boot阶段被载入的kernel的地址结尾(不知道是怎么获取的...),PHYSTOP是0xE0000000,物理内存最大值。
对于实现细节:
// Initialization happens in two phases.
// 1. main() calls kinit1() while still using entrypgdir to place just
// the pages mapped by entrypgdir on free list.
// 2. main() calls kinit2() with the rest of the physical pages
// after installing a full page table that maps them on all cores.
void
kinit1(void *vstart, void *vend)
{
initlock(&kmem.lock, "kmem");
kmem.use_lock = 0;
freerange(vstart, vend); // 注意这里的freerange就是把这个范围里的physical memory free掉
}
void
kinit2(void *vstart, void *vend)
{
freerange(vstart, vend);
kmem.use_lock = 1;
}其实也就是把对应部分的内存抹干净了。
在第二步的kvmalloc中切换了page table。
// There is one page table per process, plus one that's used when
// a CPU is not running any process (kpgdir). The kernel uses the
// current process's page table during system calls and interrupts;
// page protection bits prevent user code from using the kernel's
// mappings.
//
// setupkvm() and exec() set up every page table like this:
//
// 0..KERNBASE: user memory (text+data+stack+heap), mapped to
// phys memory allocated by the kernel
// KERNBASE..KERNBASE+EXTMEM: mapped to 0..EXTMEM (for I/O space)
// KERNBASE+EXTMEM..data: mapped to EXTMEM..V2P(data)
// for the kernel's instructions and r/o data
// data..KERNBASE+PHYSTOP: mapped to V2P(data)..PHYSTOP,
// rw data + free physical memory
// 0xfe000000..0: mapped direct (devices such as ioapic)
//
// The kernel allocates physical memory for its heap and for user memory
// between V2P(end) and the end of physical memory (PHYSTOP)
// (directly addressable from end..P2V(PHYSTOP)).
// This table defines the kernel's mappings, which are present in
// every process's page table.
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
// Set up kernel part of a page table.
pde_t*
setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
memset(pgdir, 0, PGSIZE);
if (P2V(PHYSTOP) > (void*)DEVSPACE)
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start,
(uint)k->phys_start, k->perm) < 0) {
// Free a page table and all the physical memory pages
// in the user part.
freevm(pgdir);
return 0;
}
return pgdir;
}
// Allocate one page table for the machine for the kernel address
// space for scheduler processes.
void
kvmalloc(void)
{
kpgdir = setupkvm();
switchkvm();
}
// Switch h/w page table register to the kernel-only page table,
// for when no process is running.
void
switchkvm(void)
{
lcr3(V2P(kpgdir)); // switch to the kernel page table
}需要好好读一下上面这段代码的最上面的注释。对于kvmalloc大致就是用setupkvm做了一个对于kernel部分映射了的page table,然后用switch把这个page table赋值给%cr3。这个时候就可以进行kernel部分的初始化了。
做完kernel的初始化之后,进行user的部分。userinit()中和page table相关的部分是:
if((p->pgdir = setupkvm()) == 0)
panic("userinit: out of memory?");
inituvm(p->pgdir, _binary_initcode_start, (int)_binary_initcode_size);刚刚说过setupkvm会把kernel的部分映射好。之后是inituvm。这个函数会把initcode(源码位于initcode.S)这个编译好的2进制文件映射到其起始位置,它是第一个process的最开始的二进制部分。而实际上,initcode的最开始是exec(init, argv)。而在exec的最后,有:
switchuvm(curproc);
freevm(oldpgdir);在switchuvm中有给cr3赋值:
void
switchuvm(struct proc *p)
{
if(p == 0)
panic("switchuvm: no process");
if(p->kstack == 0)
panic("switchuvm: no kstack");
if(p->pgdir == 0)
panic("switchuvm: no pgdir");
pushcli();
mycpu()->gdt[SEG_TSS] = SEG16(STS_T32A, &mycpu()->ts,
sizeof(mycpu()->ts)-1, 0);
mycpu()->gdt[SEG_TSS].s = 0;
mycpu()->ts.ss0 = SEG_KDATA << 3;
mycpu()->ts.esp0 = (uint)p->kstack + KSTACKSIZE;
// setting IOPL=0 in eflags *and* iomb beyond the tss segment limit
// forbids I/O instructions (e.g., inb and outb) from user space
mycpu()->ts.iomb = (ushort) 0xFFFF;
ltr(SEG_TSS << 3);
lcr3(V2P(p->pgdir)); // switch to process's address space
popcli();
}也就完成了user page table的初始化。
说完了整个的大框架,我们来看一下每次用户代码需要进行新内存的分配的时候,比如当遇到page fault进入trap来分配新内存的时候(lazy page allocation):
case T_PGFLT:
{
// code from allocuvm
uint newsz = myproc()->sz;
uint a = PGROUNDDOWN(rcr2());
if(a < newsz){
char *mem = kalloc();
if(mem == 0) {
cprintf("out of memory\n");
exit();
break;
}
memset(mem, 0, PGSIZE);
mappages(myproc()->pgdir, (char*)a, PGSIZE, V2P(mem), PTE_W|PTE_U);
}
break;
}最重要的就是kalloc,memset和mappages了。memset是包装了x86的分配内存的函数,再次不提。
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
char*
kalloc(void)
{
struct run *r;
if(kmem.use_lock)
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next; // 所有空内存的链表
if(kmem.use_lock)
release(&kmem.lock);
return (char*)r;
}kalloc得到一个空page的头部地址,mappages进行映射,所以归根到底所有的环境都会用同一个kmem链表分配内存。
内存分配的小技巧
-
lazy page allocation
前面提到过,先不分配内存,触发page fault的时候再分配。
-
copy on write
这个在lab4里面有实现。大致是先不复制,把对应的page仅仅map上,然后给一种新的PTE状态,在触发写的trap的时候进行复制。
-
one zero-filled page
因为很多page不会写入,所以最开始可以分配给一个公共的zero page,如果出问题了,就创建新的。
-
share kernel page mapping
共享kernel page mapping。这个不知道咋实现呢...
-
demanding paging
现在的exec可能会把整个文件都加载到内存中,这样会很慢,并且有可能没必要。可以先分配page,并标记为on demand,on default从file中读取对应的page。会遇到的挑战就是如果文件比物理内存还大怎么办?下一条会给出解决方案。
-
用比物理内存更大的虚拟内存
有的时候可能需要比物理内存还大的内存。解决方法就是把内存中不常用的部分存在硬盘上。
在硬盘和内存之间"page in" and out数据
- 使用PTE来检测什么时候需要disk access
- 用page table来找到least recent used disk block 并把其写回硬盘(LRU)
当同时使用的内存小于RAM的时候,非常work。
-
memory-mapped files
通过load, store而不是read, write, lseek来access files以轻松访问文件的某一部分
- 会使用
mmapsystem call - 用memory offset而不是seeking
- 会使用
-
distributed shared memory
用虚拟内存来假装物理内存 is shared between several machines on the network
注意只有read only page可以复制,而能够写入的不能。
The UVPD
用来让page table等访问到自己的。