zhuzilin's Blog
about
Interpreter Dispatch Techniques
date: 2021-12-29
tags: compiler
关注 interpreter dispatch 的原因是,很多人说 python 这种编译器的时间主要消耗在 dispatch 上,所以做 JIT 也没什么用。所以想学习一下一些主流的 interpreter dispatch 的方式。不过在 PEP 659 的引用文献 Inline Caching meets Quickening 中提到,提升 dispatch 对较低层的 interpreter,例如 JVM bytecode interpreter 比较有帮助,可以有成倍提升,但是对 python、perl 这种一个 opcode 对应好多好多机器码的语言帮助就不大了,测试在 python 中可以做到 benchmark 成绩提升 20%,Django 样例提升 7%~8%。一个更好的优化方式应该是去做 inline cache。
本文主要内容来自 Mathew Zaleski 的博士论文 YETI: a graduallY Extensible Trace Interpreter 的第二章。
Switch Dispatch
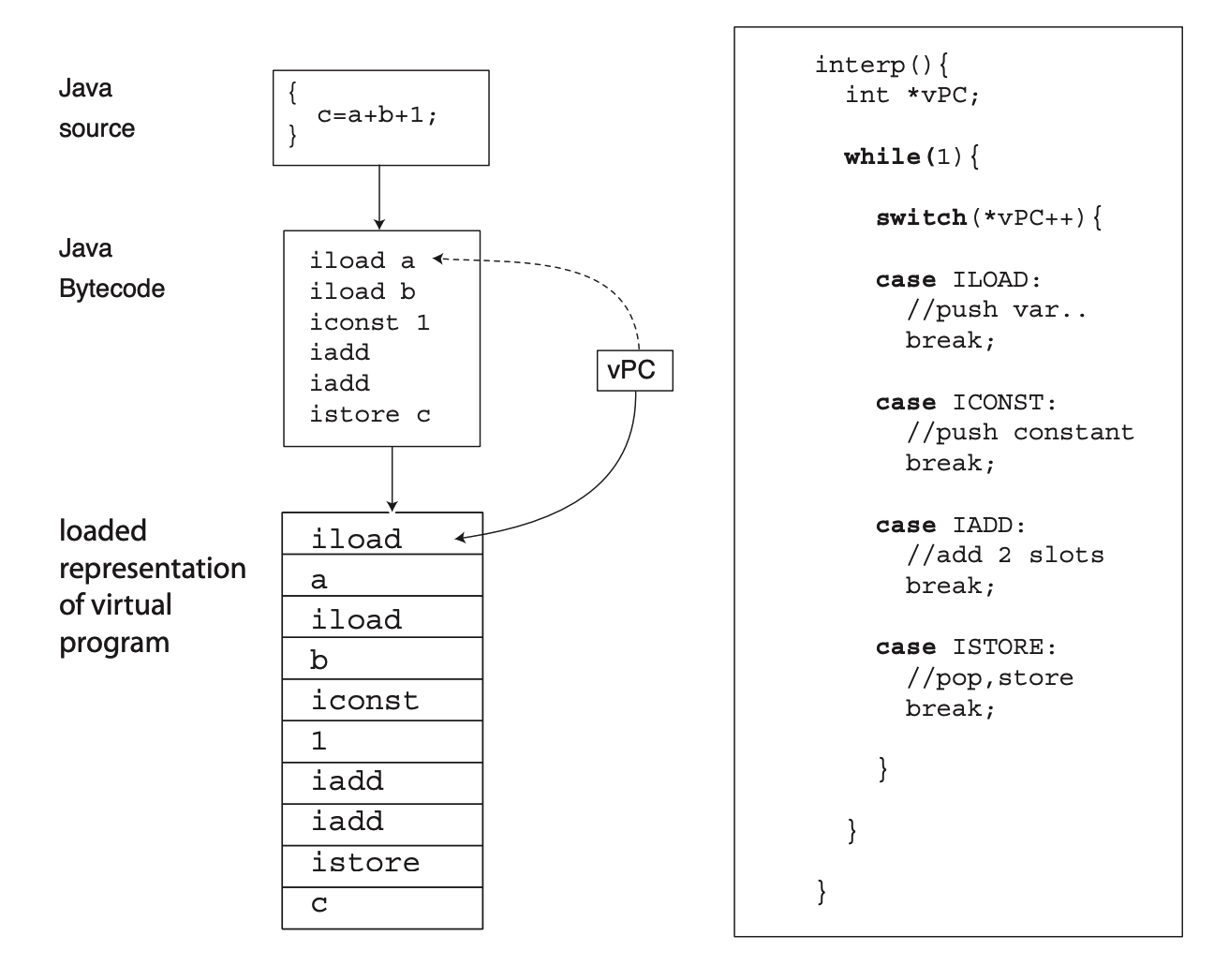
就是常见的大循环里面用 switch 来判断指令类型。
因为这个循环和 switch,这种方法很慢,然而 python 和 javascript 是用的这种方法。这种方法在 ANSI C 中很好实现,所以迁移性很好。
Direct Call Threading
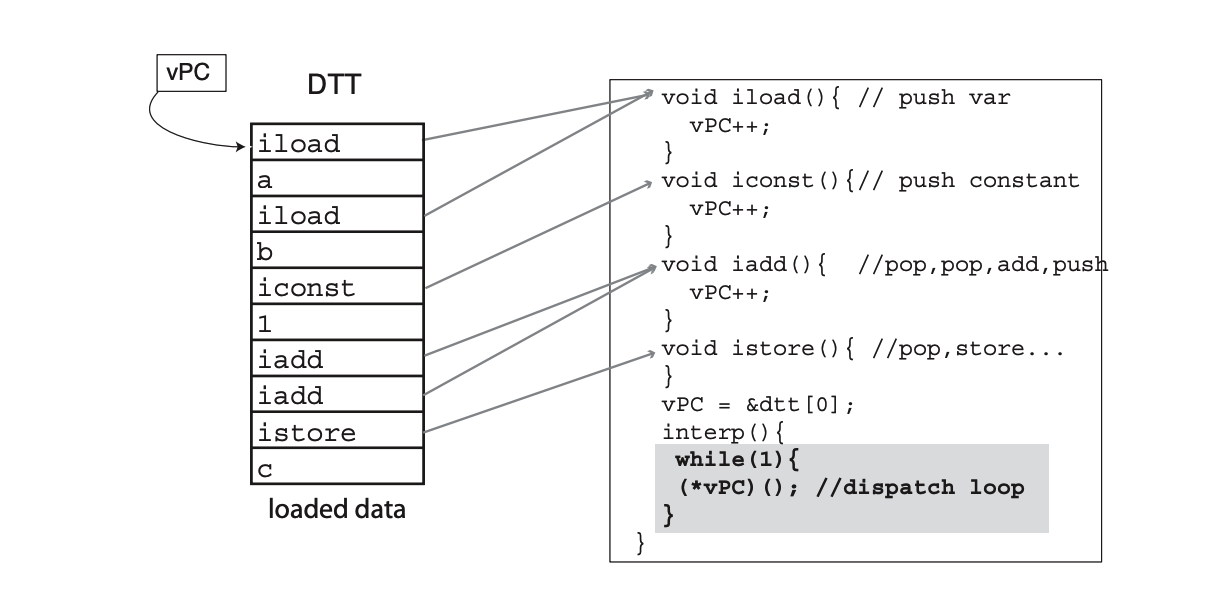
另一种方法是把每个 virtual instruction 都写成一个函数,通过调用函数指针来 dispatch 他们。由于历史原因,"direct":
For historical reasons the name "direct'' is given to interpreters which store the address of the virtual instruction bodies in the loaded representation. Presumably this is because they can "directly" obtain the address of a body, rather than using a mapping table (or switch statement) to convert a virtual opcode to the address of the body. However, the name can be confusing as the actual machine instructions used for dispatch are indirect branches. (In this case, an indirect call).
在博士论文中,论证了这种方法的性能和 switch 差不多。
Direct Threading
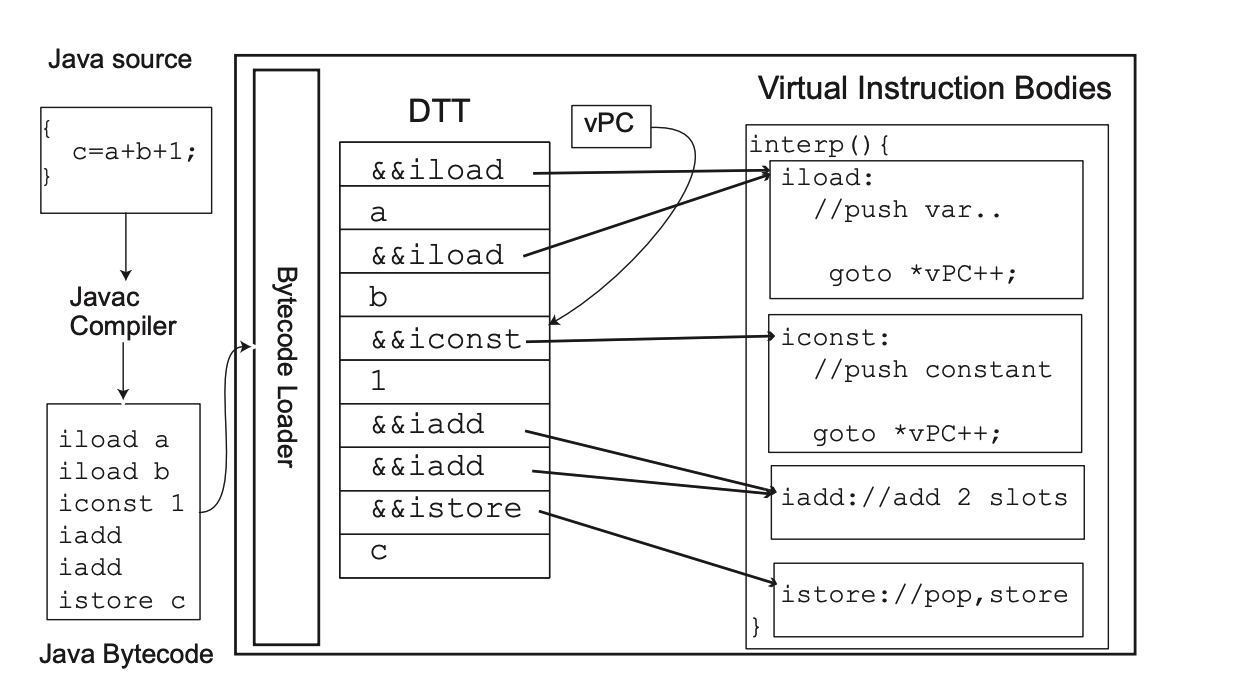
上图中 DTT 指 direct threading table。我们一般称 DTT 中的格子为 slot。
这个方法就不需要一个 loop 了,而是每一段(body)的结尾都是一个 goto。在 C 中,body 可以用 label 标识,gcc 以及一些 intel IBM 的编译器都支持把 label 当成值传,所以实现这个功能很方便。
这个方法相较于 switch 和 direct call 都要快很多,因为需要更少的指令。
上图中的 && 是 gcc 中的求址操作。
Context Problem
但是问题是在硬件层面会导致 branch mispredicting。例如上面的例子,第一次 iload 里的 goto 会跳回iload,第二次则会跳到 iconst,硬件很有可能会在第二次的的时候判断错误,这一点的性能影响很难估计。不过 switch 和 direct call 的问题更严重,因为他们只有1个 predict branch,所以基本都会判断错...我们称 the lack of correlation between the hardware pc and vpc as the context problem。
一些优化方法
superinstruction
做一些复杂的 opcode,也就是扩充指令集,比如把 add const 变成 1 个单独的加 const 的。
selective inlining
Piumarta and Riccardi [#!piumarta:inlining!#] present selective inlining[
. Selective inlining constructs superinstructions when the virtual program is loaded. They are created in a relatively portable way, by
memcpy'ing the compiled code in the bodies, again using GNU C labels-as-values. The idea is to construct (new) super instruction bodies by concatenating the virtual bodies of the virtual instructions that make them up. This works only when the code in the virtual bodies is position independent, meaning that the destination of any relative branch in a body is in that body also. Typically this excludes bodies making C function calls. Like us, Piumarta and Riccardi applied selective inlining to OCaml, and reported significant speedup on several micro benchmarks. As we discuss in Section [, our technique is separate from, but supports and indeed facilitates, inlining optimizations.
Languages, like Java, that require runtime binding complicate the implementation of selective inlining significantly because at load time little is known about the arguments of many virtual instructions. When a Java method is first loaded some arguments are left unresolved. For instance, the argument of an
invokevirtualinstruction will initially be a string naming the callee. The argument will be re-written the first time the virtual instruction executes to point to a descriptor of the now resolved callee. At the same time, the virtual opcode is rewritten so that subsequently a ``quick'' form of the virtual instruction body will be dispatched. In Java, if resolution fails, the instruction throws an exception and is not rewritten. The process of rewriting the arguments, and especially the need to point to a new virtual instruction body, complicates superinstruction formation. Gagnon describes a technique that deals with this additional complexity which he implemented in SableVM [#!gagnon:inline-thread-prep-seq!#].Selective inlining requires that the superinstruction starts at a virtual basic block, and ends at or before the end of the block. Ertl and Gregg's dynamic superinstructions [#!ertl:vm-branch-pldi!#] also use
memcpy, but are applied to effect a simple native compilation by inlining bodies for nearly every virtual instruction. They show how to avoid the basic block constraints, so dispatch to interpreter code is only required for virtual branches and unrelocatable bodies. Vitale and Abdelrahman describe a technique called catenation, which (i) patches Sparc native code so that all implementations can be moved, (ii) specializes operands, and (iii) converts virtual branches to native branches, thereby eliminating the virtual program counter [#!vitale:catenation!#].
replication
为同一个 opcode 创建多个 body,提高正确分辨的概率。