When XTX is a full rank matrix, which means, X has at least d+1 linear independent row, the solution exists.
And for polynomial regression, we could just take them as extra column for X. More generally, we could use the kernel method:
yi≈f(xi,w)=s=1∑Sgs(xi)ws
As long as the function is linear on w, the solution will always be (XTX)−1XTy.
Geometric interpretation
The columns of X define a d+1-dimensional subspace in the higher dimensional Rn. The closest point in that subspace is the orthonormal projection of y into the column space of X.
Probabilistic interpretation
Assume
p(y∣μ,σ2I)=N(μ=Xw,σ2I)
Then the maximum likelihood (ML) estimator would be
wML=argwmaxlnp(y∣Xw,σ2I)=argwmin∣∣y−Xw∣∣2
Therefore, using least square is making an independent Gaussian noise assumption about error.
And also from this probabilistic assumption
E[wML]=(XTX)−1XTE[y]=(XTX)−1XTXw=w
wML is unbiased. And similarly we could calculate the variance:
Var[wML]=σ2(XTX)−1
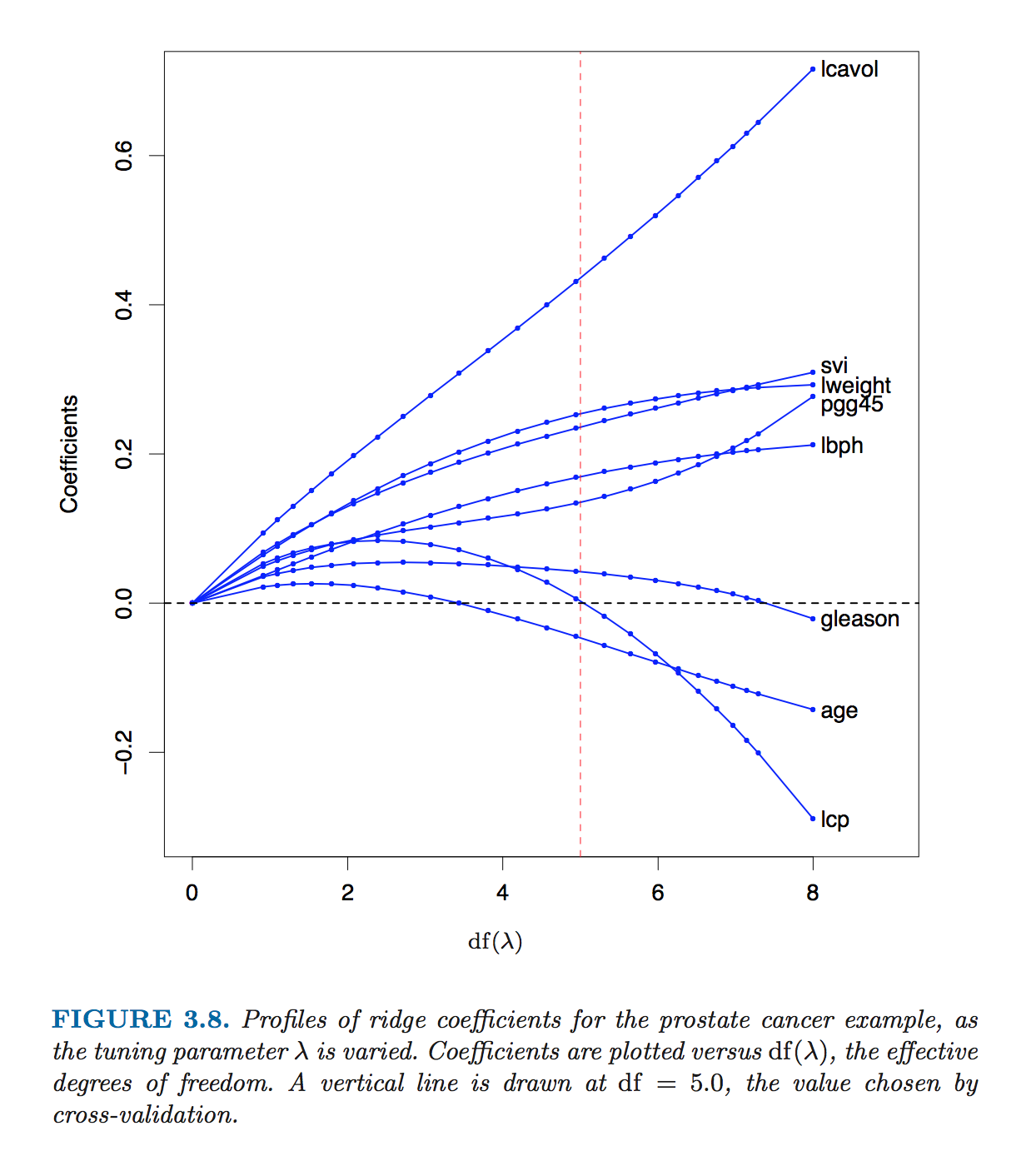
Therefore, when σ2(XTX)−1 is large, wML may be huge. And to prevent this, we need to introduce regularization.
Ridge Regression
For the general linear regression with regularization, the model is
wLS=argwmin∣∣y−Xw∣∣2+λg(w)
where λ>=0, g(w)>=0.
And ridge regression is one of them,
wLS=argwmin∣∣y−Xw∣∣2+λ∣∣w∣∣2
And we could solve the answer
L=∣∣y−Xw∣∣2+λ∣∣w∣∣2=(y−Xw)T(y−Xw)+λwTw
wRR=(λI+XTX)−1XTy
There is a tradeoff between square error and penalty on the size of w.
E[wRR]=Zw
and
Var[wRR]=σ2Z(XTX)−1ZT
where Z=(I+λ(XTX)−1)−1.
RR gives us a solution that is biased, but has lower variance than LS.
Data preprocessing
For ridge regression, we assume the following preprocessing:
The mean is subtracted off of y
y←y−n1i=1∑nyi
The dimension of xi have been standardized before constructing X:
xij←(xij−xˉ.j)/σ^j
We can show that there is no need for the dimension of 1's in this case.
Probabilistic interpretation
If we set the prior distribution for w as w∼N(0,λ−1I), then
We will maximize over η and minimize over w. (So much like how to derive the dual form for linear programming!). And this would force Xw=y.
And the optimality gives us
∇wL=2w+XTη=0,∇ηL=Xw−y=0
From the first condition we have: w=−XTη/2
Plug #1 into second condition to find: η=−2(XXT)−1y
Plug #2 back into #1 to find: wln=XT(XXT)−1y
LASSO
LS and RR are not suited for high-dimensional data, because:
They weight all dimensions without favoring subsets of dimensions.
The unknown “important” dimensions are mixed in with irrelevant ones.
They generalize poorly to new data, weights may not be interpretable.
LS solution not unique when d > n, meaning no unique predictions.
One intuition why RR is not good for high dimensional data is that the quadratic penalty will reduce more when reducing the larger terms, and will leave all terms of w small but not 0.
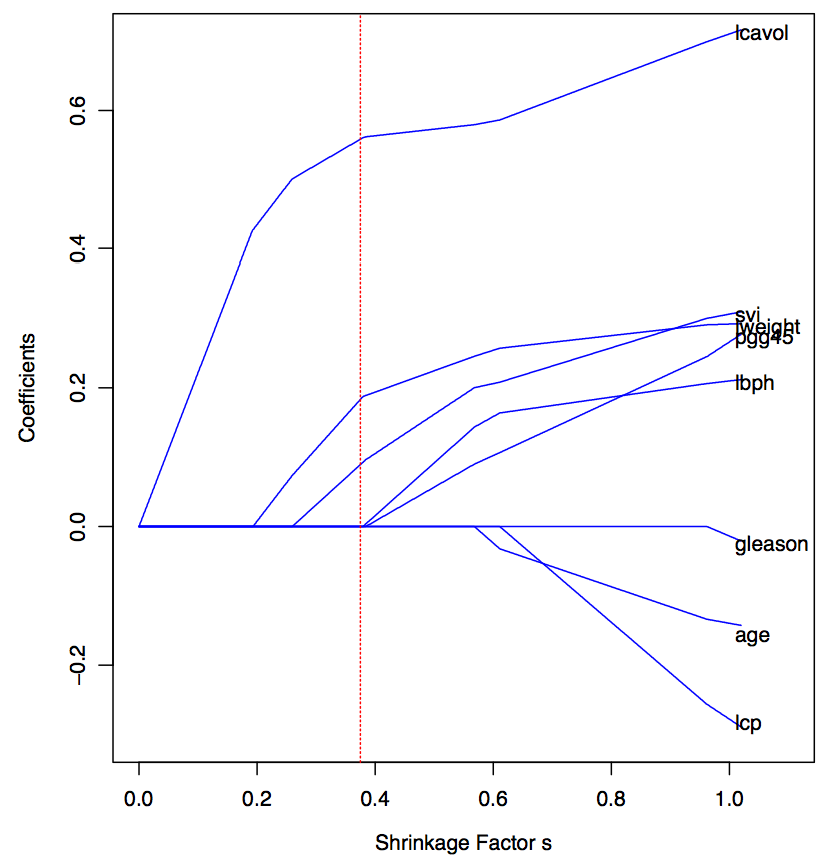
And to find a sparse solution (solution with many 0s), we need to use a linear penalty term. And that is why we introduce LASSO.
Model definition
wlasso=argwmin∣∣y−Xw∣∣22+λ∣∣w∣∣1
where ∣∣w∣∣1=∑i=1d∣wj∣.
With this penalty, the cost reduction does not depend on the magnitude of wj, which helps to get a sparse solution.
From the above figure, we could observe that with the increasing of λ, which is the decreasing of df(λ), the weight will goes to 0 and will stay at 0. (In some special case, they may leave 0, but it's rare).
And more generally speaking, there is lp regression, where p=1 is LASSO and p=2 is RR. And notice when p<1, the penalty is no longer convex and we cannot get an global optimum.
Greedy Sparse Regression
We will use the LS to help pick the sparse solution. And the algorithm we used here is called orthogonal matching pursuits, as its name suggests, we would gradually add the Xj, which is the column of X to our solution if Xj has the smallest angle with the residue. To be more specific, there are two steps:
Find the least squares solution and the residual,
wLSk=(XIkTXIk)−1XIkTy,r(k)=y−XIkwLS(k)
Add the column of X to Ik that correlates the most with the error,
Pick jth column of X, (called Xj), where j=argmaxj′∣∣Xj′∣∣2∣∣r(k)∣∣2∣Xj′Tr(k)∣
Least Absolute Deviation
Model Definition
wLAD=argwmini=1∑n∣yi−f(xi;w)∣
It is no explicit solution for LAD, but we can find one using linear programming.
Probabilistic Interpretation
If we assume the error has a Laplace distribution, which is