zhuzilin's Blog
about
尝试 GPU Direct Storage 宣告失败
date: 2021-11-19
tags: OS
这两天我突然发掘了 GPU Direct Storage (后文都称 gds)这个东西,他可以允许从 GPU 显存到 NVMe 或支持 RDMA 的文件系统的 DMA。虽然好像是在 19 年就发布了,但是在 cuda 11.4 之前,这个东西主要是应用在 RAPDIS 里面,例如 spark-rapids 中。cuda 11.4 中把这部分放进 cuda 了,也终于标志成了 1.0。
而且 GPU Storage 也退出了一个非常方便的接口:cuFile。可以用下面两段代码从文件读取数据到 GPU 的代码对比一下。
POSIX API:
int fd = open(...)
void *sysmem_buf, *gpumem_buf;
sysmem_buf = malloc(buf_size);
cudaMalloc(gpumem_buf, buf_size);
pread(fd, sysmem_buf, buf_size);
cudaMemcpy(sysmem_buf,
gpumem_buf, buf_size, H2D);
doit<<<gpumem_buf, …>>> cuFile API:
int fd = open(file_name, O_DIRECT,...)
CUFileHandle_t *fh;
CUFileDescr_t desc;
desc.type=CU_FILE_HANDLE_TYPE_OPAQUE_FD;
desc.handle.fd = fd;
cuFileHandleRegister(&fh, &desc);
void *gpumem_buf;
cudaMalloc(gpumem_buf, buf_size);
cuFileRead(&fh, gpumem_buf, buf_size, …);
doit<<<gpumem_buf, …>>> 可以看到 cufile 使用起来还是非常自然的。所以我本来计划得可好了,既然 gds 可以将硬盘文件直接传到 GPU ,可以做一个 gds 版本的 embedding,在 CPU 中记录 feature key 在硬盘文件的位置,在硬盘上记录实际的 embedding。这样至少可以提升在推荐场景下单机能够承载的 embedding 大小。如果想做的更复杂一些,没准可以整一个结合 GPU 的 lmdb(B 树)。这里想用 B 树是因为感觉 LSM 那种形式和 embedding 有些不搭。
不过这些美好的计划很快被现实击碎了。
首先是装环境,官方表示只有在 ubuntu 18.04, 20.04 或者 RHEL 8.4 上才有支持的 cuda,并且还不能用 .run 文件,而是要用下面这样的方式安装:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.5.0/local_installers/cuda-repo-ubuntu2004-11-5-local_11.5.0-495.29.05-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-5-local_11.5.0-495.29.05-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-5-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda因为公司内网下载外链极慢,所以整了快一天才下下来。结果发现 apt install cuda 是会伴随着指定的 driver 版本的。具体来说是会装一个 495 版本的驱动...公司里的驱动版本自然是没有那么高的,所以这个安装直接把镜像搞崩了,连 nvidia-smi 都跑不了了。
不过好在,我直接跑到 cuda 目录下头,把 cufile.h 以及 libcufile.so 搞出来了。用他们在以前的 cuda 11.0 的镜像里面编译是可以运行的。
虽然能跑了,但是实际上因为并没有装上指定的环境,所以按照文档说的,cufile 会运行兼容模式,就还是先分配 pin memory buffer,然后一点一点拷贝...
Although the purpose of GDS is to avoid using a bounce buffer in CPU system memory, the ability to fall back to this approach allows the cuFile APIs to be used ubiquitously even under suboptimal circumstances. A compatibility mode is available for unsupported configurations that maps IO operations to a fallback path.
This path stages through CPU system memory for systems where one or more of the following conditions is true:
Explicit configuration control by using the user version of the
cufile.jsonfile.The lack of availability of the
nvidia-fs.kokernel driver, for example, because it was not installed on the host machine, where a container with an application that uses cuFile, is running.The lack of availability of relevant GDS-enabled filesystems on the selected file mounts, for example, because one of several used system mounts does not support GDS.
File-system-specific conditions, such as when
O_DIRECTcannot be applied.
为了不使用兼容模式,需要安装一个 nvidia-fs.ko kernel driver。所以其实到这里我的应用之路就卡死了。因为我们的应用都是在镜像中进行的,是没法装 kernel module 的。之前薛磊大大的 fgpu 也是用的同样的技术,也是需要用母机部署。
但是既然时间已经花出去了,直接到这里结束就太可惜了。所以不如继续研究几个问题。
- 为啥镜像里面不能配置 kernel?
因为 docker 里的容器其实就是一个进程,所以其一直是用的是 host kernel,syscall 也会直接走到 host kernel 去。而 container 里是没有 kernel 或者 kernel module 的。所以在 container 里面注册也并不会注册上。
- gds 为啥需要装一个 kernel module?为啥 gds 只能从 NVMe 文件读数据,或者是从支持 RDMA 的分布式文件系统中读数据?
下图是 gds 的一个结构:
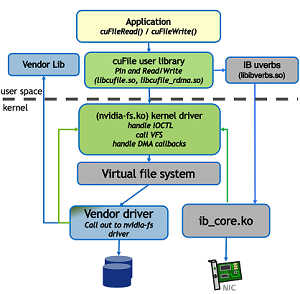
可以看到 cuFile 的实现方法是像 kernel module 发只有它能识别的 ioctl(ioctl 应该是 VFS 的一部分,所以派发 ioctl 应该是 VFS 做的),然后由这个 nvidia-fs.ko 实现从文件系统到显存的 DMA。
实际上,nv 也开源了这个 kernel module:github 链接。所以我也偷偷尝试去编译了一下,结果发现他是需要 /usr/src/nvidia-* 这个位置的 driver 源码的。这种东西在镜像里是得不到的,所以也就没有办法了。这里我不太了解 /usr/src/ 目录里到底是有啥,毕竟众所周知 nv 的驱动是闭源的,所以对应的目录里面肯定不是源码,可能是类似于 .so 的东西吧。